



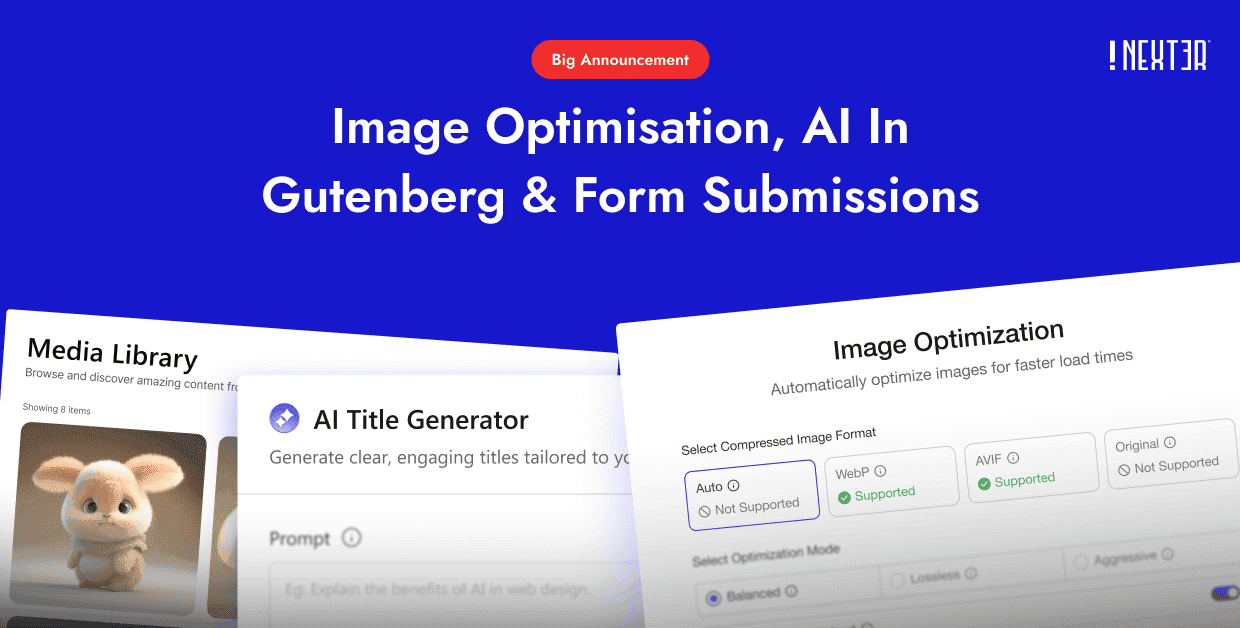


Key Takeaways
- ClaudeBot is Anthropic’s web crawler. Anthropic says it collects web content that could potentially contribute to training its generative AI models.
- It is one of three Anthropic agents: ClaudeBot (training), Claude-User (fetches a page when a Claude user asks about it), and Claude-SearchBot (improves Claude search results).
- Anthropic says its crawlers respect robots.txt. To block ClaudeBot, add a User-agent: ClaudeBot rule with Disallow: / to your robots.txt file.
- Blocking keeps your content out of training, but it can also keep you out of the answers Claude gives its users. It is a trade-off, not an obvious yes or no.
- RankReady lets you allow or block ClaudeBot and 30 more AI crawlers from one dashboard, and its live log shows whether ClaudeBot actually visits your site.
The first time most site owners hear about ClaudeBot is in a server log. A user agent you do not recognize is fetching pages, sometimes a lot of them, and the name points back to Anthropic, the company behind Claude. The immediate question is the same one people asked about GPTBot a year earlier: do I let this thing read my site, or do I shut the door?
There is no single right answer, but there is a clear way to decide. This guide explains what ClaudeBot is in Anthropic’s own words, how it differs from the other Anthropic agents, the honest case for allowing or blocking it, and the exact steps to control it on WordPress.
What Is ClaudeBot?
ClaudeBot is the web crawler operated by Anthropic. In Anthropic’s own documentation, ClaudeBot “helps enhance the utility and safety of our generative AI models by collecting web content that could potentially contribute to their training.” In plain terms, it reads public web pages, and that content may feed into the data Anthropic uses to train Claude.
It identifies itself with the user agent ClaudeBot. Anthropic also states that its bots “respect ‘do not crawl’ signals by honoring industry standard directives in robots.txt,” and that they support the non-standard Crawl-delay directive for rate limiting. So unlike a scraper that ignores the rules, ClaudeBot is designed to obey a correctly written robots.txt file.
ClaudeBot vs Claude-User vs Claude-SearchBot
Anthropic runs more than one agent, and they do different jobs. Blocking one does not block the others, so it helps to know which is which before you write any rules.
| Agent | What Anthropic says it does |
|---|---|
| ClaudeBot | Collects web content that could potentially contribute to training Anthropic’s generative AI models. |
| Claude-User | Supports Claude AI users. When individuals ask questions, Claude may access websites using the Claude-User agent. |
| Claude-SearchBot | Navigates the web to improve search result quality, analyzing content to enhance the relevance and accuracy of search responses. |
The distinction matters. ClaudeBot is about training. Claude-User is the agent that fetches your page in real time because a person asked Claude something your content can answer, which is the closest thing to an AI citation visit. If you block everything Anthropic, you also turn off the agent that could surface your site inside Claude’s answers.
Also Read: What Is GPTBot? covers the same allow-or-block decision for OpenAI’s crawler.
Should You Allow or Block ClaudeBot?
This is a real trade-off, and reasonable site owners land on both sides.
The case for blocking: you may not want your content used to train a commercial AI model, especially if you sell that content, run a membership site, or simply object on principle. Blocking ClaudeBot is a clear way to opt out of training collection. High-traffic crawling can also add server load, though Anthropic’s Crawl-delay support gives you a softer option than a full block.
The case for allowing: AI assistants are becoming a real discovery channel. If your goal is to be mentioned and cited when people ask Claude about your topic, blocking Anthropic’s agents works against you. For most publishers, marketers, and businesses who want visibility in AI answers, allowing the crawlers is the more strategic choice. The honest middle ground is to allow Claude-User (the answer-time agent) even if you are unsure about ClaudeBot (the training agent), so you stay eligible for citations without contributing to training.
How to Block (or Allow) ClaudeBot on WordPress
Because ClaudeBot honors robots.txt, control comes down to the rules in that file. To block ClaudeBot entirely, Anthropic recommends adding this:
User-agent: ClaudeBot
Disallow: /To allow ClaudeBot, you simply do not add a Disallow rule for it, since crawling is allowed by default. If you want to keep the training crawler out but stay available for answer-time visits, write a rule that blocks ClaudeBot while leaving Claude-User alone. On WordPress, you can edit robots.txt through your SEO plugin or a dedicated robots.txt editor. The catch is that hand-editing robots.txt for one crawler at a time is fiddly and easy to get wrong, and a single typo in a user-agent name means the rule silently does nothing.
Also Read: WordPress robots.txt for AI Crawlers walks through the full file for every major AI bot.
The Easier Way: Manage AI Crawlers With RankReady
If you would rather not maintain robots.txt by hand, RankReady turns crawler control into toggles. It is a free, GPL-2.0 plugin for WordPress 6.0 and PHP 7.4 or higher, and it runs alongside Rank Math, Yoast, AIOSEO, SEOPress, The SEO Framework, and Slim SEO. To be clear about the boundary: RankReady controls whether crawlers can access your site; it does not change what Anthropic does with content it has already collected.
- Allow or block 31 AI crawlers individually: ClaudeBot, GPTBot, PerplexityBot, Google-Extended, Bytespider, and 26 more, each with its own toggle instead of a hand-written rule.
- Live AI crawler log: see ClaudeBot and the other bots actually visiting, with timestamp and page, so you know whether your block worked or whether allowing it is paying off.
- Citation candidates: a leaderboard of the posts that citation-style bots fetched in the last 30 days, so you can connect crawler access to real AI visibility.
- AI referral traffic: tracks visits arriving from claude.ai, chatgpt.com, perplexity.ai, and gemini.google.com.
Whichever way you lean, the smart move is to make the choice deliberately and then verify it. Decide whether Anthropic’s training crawler fits your goals, allow the answer-time agent if AI visibility matters to you, and watch the log to confirm what is really happening. You can try RankReady for free to manage and monitor ClaudeBot on your own site.
Suggested Reading
- What Is GPTBot? Should You Allow or Block OpenAI’s Crawler on WordPress
- ChatGPT-User: Should You Allow or Block It on Your WordPress Site?
- OAI-SearchBot: The Crawler That Decides Whether ChatGPT Search Can Find You
- WordPress robots.txt for AI Crawlers: A Gutenberg Builder Guide
- Answer Engine Optimization (AEO): The Complete WordPress Guide for 2026